Najnowsze funkcjonalności .NET Core 3.0 mimo tego, że istnieją już od ponad roku, wciąż rzadko są stosowane w aplikacjach. W artykule przyjrzyjmy się, jakie korzyści mogą wynikać z wykorzystania instrukcji AVX2 w nowoczesnym kodzie, a także zobaczymy powód, dla którego należy unikać stosowania LINQ w krytycznych częściach kodu.
Niedawno otrzymałem filmik opisujący kilka rad o tym, jak zwiększyć wydajność aplikacji, dzięki pewnym sztuczkom. Zainteresowanych jego treścią odsyłam do źródła[1]5 (Extreme) Performance Tips in C#. Dlaczego wspominam o nim? Autor przedstawia kilka ciekawych sztuczek optymalizacyjnych, jednak całkowicie pomija hardware intrinsics – pewnego rodzaju nowinkę, dodaną w .NET Core 3.0, czyli trochę ponad rok temu.
Przyspieszenie sprzętowe?
Współczesne procesory architektury x86 zawierają w sobie wiele dodatkowych zestawów instrukcji. Jednym z nich jest Advanced Vector Extensions, czyli w skrócie AVX[2]Advanced Vector Extensions – Wikipedia. Umożliwia to wykonywanie operacji na wektorach, czyli zestawach liczb, co przekłada się na mniej cyklów procesora potrzebnych do otrzymania wyniku. Przykładowo, jeśli chcemy dodać do siebie 100 liczb, możemy dodawać je klasycznie, do pierwszej dodać drugą, do ich sumy trzecią, do tej sumy czwartą i tak dalej. Zajmie nam to dokładnie 100 cykli procesora, po jednym na każde dodawanie.
Zamiast tego możemy dodawać te liczby wektorem 8-elementowym – działa to w ten sposób, że w jednym cyklu procesora dodawany jest element pierwszy z dziewiątym, drugi z dziesiątym, trzeci z jedenastym i tak dalej. Dzięki temu potrzebujemy 12 cykli procesora na dodanie 96 elementów. Następnie te elementy sumujemy – co daje 8 cykli, a do ich sumy dodajemy brakujące cztery elementy, co daje kolejne 4 cykle. Łącznie 24 cykle zamiast 100.
Wszystko pięknie… Ale?
Ten wzrost wydajności ma swoje wymagania. Przede wszystkim – procesor, na którym będzie uruchamiany program musi zawierać zestaw rozkazów AVX – na szczęście większość współczesnym procesorów ją posiada. Oprócz tego z powodu, w jaki działają wektory, wymagane są wskaźniki do pamięci (jeśli Cię to dziwi – to tak, w C# można korzystać z wskaźników na tej samej zasadzie, co choćby w C++, więcej o tym wkrótce), co oznacza niebezpieczny (unsafe) kod. Wymaga to też odrobinę wiedzy, na szczęście to ostatnie właśnie Ci dostarczamy 🙂
Wymagania wstępne
Hardware Intrinsics wymaga .NET Core 3.0 lub nowszego oraz ustawienia flagi /unsafe w kompilatorze. Jeśli nie wiesz jak zainstalować .NET Core to najprawdopodobniej ten poradnik nie jest dla Ciebie, jednak nie zniechęcaj się – pobierzesz go bezpośrednio z strony Microsoftu[3]https://dotnet.microsoft.com/download/dotnet-core/.
Flagę /unsafe można dodać modyfikując plik projektu i ustawiając AllowUnsafeBlocks na true lub potwierdzając podpowiedź wyświetlaną przez Visual Studio.
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netcoreapp3.1</TargetFramework>
</PropertyGroup>
<PropertyGroup Condition="'$(Configuration)|$(Platform)'=='Release|AnyCPU'">
<AllowUnsafeBlocks>true</AllowUnsafeBlocks>
<DebugType>full</DebugType>
<DebugSymbols>true</DebugSymbols>
</PropertyGroup>
<PropertyGroup Condition="'$(Configuration)|$(Platform)'=='Debug|AnyCPU'">
<AllowUnsafeBlocks>true</AllowUnsafeBlocks>
</PropertyGroup>
</Project>
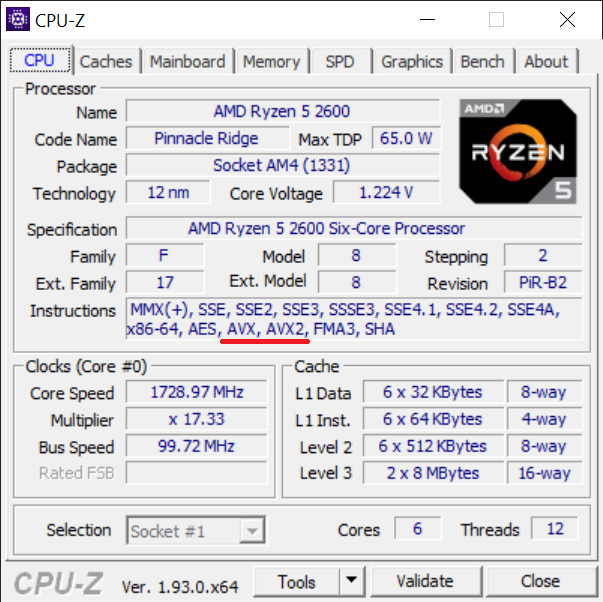
Jeśli nie posiadasz procesora z instrukcjami AVX – niestety nie będziesz w stanie sam sprawdzić, jak działa kod. Jeśli nie jesteś pewien czy go posiadasz, to program CPU-Z[4]CPUID website pokazuje wszystkie informacje na temat procesora, w tym czy implementuje on AVX.
Całkiem szybki kod bez Hardware Intrinsics
Najpierw zerknijmy na fragment kodu z wspomnianego filmiku, jeden z najszybszych a przy tym dość prosty. Dla osób, które nie oglądały filmiku – celem jest znalezienie jak najszybszej metody na zsumowanie wszystkich nieparzystych liczb z pewnej tablicy. Pełny kod można obejrzeć na naszym GitHubie[5]GitHub – HwIntrinsincsBenchmark
public int SumOdd()
{
var counterA = 0;
var counterB = 0;
var counterC = 0;
var counterD = 0;
unsafe
{
fixed (int* data = &array[0])
{
var p = data;
for (var i = 0; i < array.Length; i += 4)
{
counterA += (p[0] & 1) * p[0];
counterB += (p[1] & 1) * p[1];
counterC += (p[2] & 1) * p[2];
counterD += (p[3] & 1) * p[3];
p += 4;
}
}
}
return counterA + counterB + counterC + counterD;
}Jest to odrobinę zmodyfikowana wersja przedostatniego przykładu z filmiku. Jedyną zmianą jest explicite dodanie bloku unsafe.
Kod choć niecodzienny, jest dość prosty, mamy cztery liczniki, do których dodajemy liczby, jeśli są nieparzyste. Wynika to z faktu, że operacja bitowego i (&) zwróci 1, jeśli ostatni bit ustawiony jest na 1 (czyli liczbę nieparzystą), w przeciwnym wypadku zwróci 0. Następnie mnożymy sprawdzaną liczbę razy tę zwróconą wartość, jak wiadomo 1 * liczba = liczba, 1 * 0 = 0. Jest to odrobinę szybszy sposób, niż instrukcja if.
Wykorzystanie AVX
public int SumUsingVectors()
{
int sum = 0;
var itemsCountUsingVectors = _array.Length - _array.Length % Vector256<int>.Count;
var template = Enumerable.Repeat(1, Vector256<int>.Count).ToArray();
var sumVector = Vector256<int>.Zero;
unsafe
{
Vector256<int> templateVector;
fixed (int* templatePtr = template)
{
templateVector = Avx.LoadVector256(templatePtr);
}
fixed (int* valuesPtr = _array)
{
for (var i = 0; i < itemsCountUsingVectors; i += Vector256<int>.Count)
{
var valuesVector = Avx.LoadVector256(valuesPtr + i);
var andVector = Avx2.And(valuesVector, templateVector);
var multiplyVector = Avx2.MultiplyLow(andVector, valuesVector);
sumVector = Avx2.Add(sumVector, multiplyVector);
}
}
}
for (var iVector = 0; iVector < Vector256<int>.Count; iVector++)
{
sum += sumVector.GetElement(iVector);
}
for (var i = itemsCountUsingVectors; i < _array.Length; i++)
{
sum += (_array[i] & 1) * _array[i];
}
return sum;
}Na pierwszy rzut oka widać, że kod jest dłuższy, więc przejdźmy przez całość.
Na początku wyliczamy, ile maksymalnie elementów jesteśmy w stanie policzyć wektorami – jeśli w jednym wektorze zmieści się 8 elementów, to będzie to podłoga z dzielenia liczby wszystkich elementów przez 8 (np. 100/8 = 12.5, czyli możemy użyć maksymalnie dwunastu ośmioelementowych wektorów).
Następnie tworzymy tablicę zawierającą same „1” – przyda się później.
W kolejnym kroku tworzymy wektor, do którego będziemy sumować.
W tym miejscu wchodzimy do niebezpiecznego (unsafe) kodu. Pierwszym krokiem jest załadowanie tablicy zawierającej same „1” jako wektor. Używamy do tego wskaźnika pokazującego na początek tablicy.
Poniżej pobieramy kolejny wskaźnik – na tablicę, która zawiera dane. Następnie wchodzimy w pętlę, która wykona się tyle razy, ile na początku wyliczyliśmy, że jesteśmy w stanie obliczyć wektorami.
W środku pętli ładujemy do wektora wartości z tablicy, wykonujemy operację AND na nim oraz na wektorze z samymi jedynkami. Wynik tej operacji mnożymy przez wektor wartości, a iloczyn dodajemy do wektora z sumą.
Jeśli przez chwilę zastanowimy się nad zawartością pętli, to szybko zauważymy, że są to dokładnie te same operacje, które są wykorzystywane w środku pętli w filmiku z YouTube, tylko wykonywane na wektorach zamiast na liczbach: Avx2.And to odpowiednik &, Avx2.MultiplyLow to odpowiednik mnożenia, a Avx2.Add to odpowiednik dodawania.
Poza blokiem unsafe sumujemy wartości z wektora wynikowego do jednej liczby, a następnie do niej dodajemy brakujące elementy.
Benchmarki
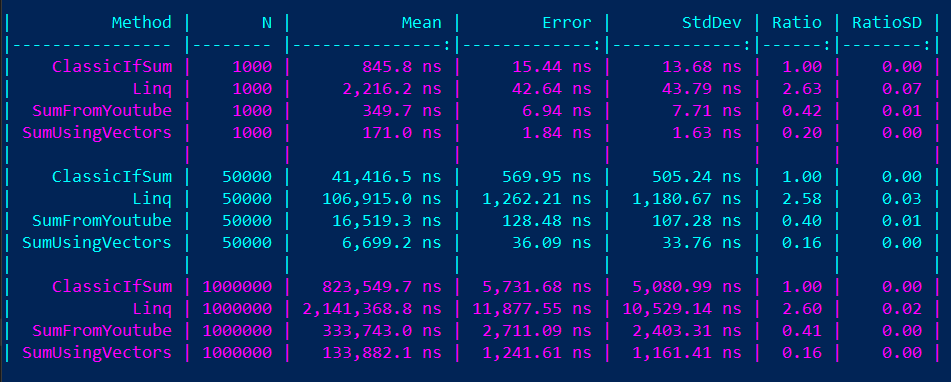
Poniżej dołączam screenshot z wynikami wygenerowanymi, dzięki Benchmark .NET[6]Mierzenie wydajności implementacji dzięki BenchmarkDotNet, ClassicIfSum to najbardziej standardowy algorytm do tego typu obliczeń, zawierający if i operację modulo 2. Do niego porównujemy pozostałe wyniki. SumFromYoutube to oczywiście kod zaczerpnięty z filmiku, SumUsingVectors to nasza implementacja. Dodałem do tego wywołanie przy pomocy LINQ: _array.Where(t => t % 2 != 0).Sum(); zdecydowanie najprostsze do zakodowania i zdecydowanie najwolniejsze.
Z wyników widać, że optymalizacja YouTubera dała 58-60% wzrostu wydajności w porównaniu do bazy, natomiast nasza dała 61% wzrostu wydajności w porównaniu do kodu YouTubera i aż 84% w porównaniu do klasycznej implementacji.
Dodatkowo LINQ było wolniejsze o odpowiednio 633% do nawet 1610% w przypadku naszego kodu.
Na koniec dodam, że kod ten można jeszcze przyspieszyć, wykorzystując wyrównanie pamięci, jednak jest to temat na osobny artykuł. Jeśli jesteście nim zainteresowani to dajcie znać!
Podsumowanie
Najnowsze wersje .NET dają bardzo dużo narzędzi do pogłębienia optymalizacji kodu w współczesnych aplikacjach. Dzięki najnowszym funkcjonalnościom możemy pisać kod szybszy niż kiedykolwiek wcześniej. Z analizy benchmarków dowiedzieliśmy się też, żeby nie używać LINQ w miejscach, które są krytyczne dla wydajności systemu.