Nierzadko w różnego rodzaju aplikacjach można spotkać się z kodem, który sprawdza, czy dana kolekcja zawiera jakieś elementy. W wielu przypadkach, gdy tablica lub lista jest pusta, to można wcześniej przerwać kod. Programiści otrzymują kilka możliwości na sprawdzenie tego warunku. Wydajnością najpopularniejszych rozwiązań zajmiemy się w tym artykule.
Count() == 0 vs Any()
Każda osoba programująca w C# spotkała się z LINQ – pomocniczymi klasami rozszerzającymi funkcjonalność innych klas. Jednymi z najczęściej wykorzystywanych są te, które rozszerzają interfejs IEnumerable. Dzięki nim dostajemy takie metody jak Select(), Count() czy Any(). Tu szczególnie będą nas interesować ostatnie dwie spośród wymienionych.
Count() == 0
Metoda Count() zwraca liczbę elementów znajdujących się w enumeracji, czyli np. liczbę elementów listy, ilość wywołań yield return pewnej metody czy liczbę par klucz-wartość w słowniku. Jednak jeśli zajrzymy do jej wnętrza odkryjemy, że zanim przystąpi do liczenia sprawdza kilka warunków:
if (source == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.source);
}
if (source is ICollection<TSource> collectionoft)
{
return collectionoft.Count;
}
if (source is IIListProvider<TSource> listProv)
{
return listProv.GetCount(onlyIfCheap: false);
}
if (source is ICollection collection)
{
return collection.Count;
}
int count = 0;
using (IEnumerator<TSource> e = source.GetEnumerator())
{
checked
{
while (e.MoveNext())
{
count++;
}
}
}
return count;
Jak widać, kod najpierw sprawdza, czy to, co próbujemy policzyć, nie jest nullem, następnie czy nie implementuje jednego z interfejsów, które mają prostszą logikę (np. w przypadku listy przechowywana jest informacja o liczbie elementów w jej środku, więc nie trzeba ich za każdym razem liczyć od początku) i dopiero, gdy żaden ze skrótów nie zadziała, uruchamiane jest „manualne” liczenie elementów.
Any()
Metoda Any(), jak nazwa wskazuje, sprawdza, czy w środku enumeracji znajduje się jakikolwiek element. Dodatkowo ta sama metoda pozwala na sprecyzowanie warunków, które musi spełnić element, aby został zaliczony. Tym jednak zajmiemy się innym razem. Podobnie jak w przypadku poprzedniej metody, zajrzyjmy do środka. Tym razem jednak mamy dwie różne odpowiedzi.
Przed .NET 5.0
if (source == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.source);
}
using (IEnumerator e = source.GetEnumerator())
{
return e.MoveNext();
}
Już na pierwszy rzut oka widać, że kod jest znacznie krótszy. Czy oznacza to, że jest lepszy (czyt. szybszy)? Zanim przejdziemy do benchmarków, zastanówmy się nad tym. W kodzie nie ma skrótów przechodzących do specyficznych przypadków, przez co nie tracimy czasu, gdy korzystamy ze zwyczajnej enumeracji. Z drugiej strony, jeśli faktycznie odpalamy ten kod np. na liście – będziemy musieli i tak zaalokować enumerator, co może negatywnie wpłynąć na wydajność.
.NET 5.0 wzwyż
if (source == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.source);
}
if (source is ICollection collectionoft)
{
return collectionoft.Count != 0;
}
else if (source is IIListProvider listProv)
{
// Note that this check differs from the corresponding check in
// Count (whereas otherwise this method parallels it). If the count
// can't be retrieved cheaply, that likely means we'd need to iterate
// through the entire sequence in order to get the count, and in that
// case, we'll generally be better off falling through to the logic
// below that only enumerates at most a single element.
int count = listProv.GetCount(onlyIfCheap: true);
if (count >= 0)
{
return count != 0;
}
}
else if (source is ICollection collection)
{
return collection.Count != 0;
}
using (IEnumerator e = source.GetEnumerator())
{
return e.MoveNext();
}
W najnowszej wersji .NET zostały wprowadzone pewne skróty. Dzięki nim można przede wszystkim uniknąć alokacji enumeratora, co ma ogromny wpływ na wydajność.
Optymalizacja aplikacji to jeden z ważniejszych etapów tworzenia szybkich aplikacji. Praktycznie każdy algorytm można zaimplementować na więcej, niż jeden sposób[1]Maksimum wydajności w aplikacjach .NET dzięki Hardware Intrinsics. Programiści jednak często stają przed dylematem: skąd wiedzieć, która wersja jest szybsza, albo czy zmiany, które w teorii powinny zwiększyć wydajność, nie robią przypadkiem czegoś dokładnie odwrotnego. Ręczne mierzenie czasu wykonywania implementacji wiąże się z wieloma pytaniami i wątpliwościami, jak zrobić to dobrze, aby wyniki były jak najbardziej reprezentatywne. Z odpowiedzią przychodzi BenchmarkDotNet.
Nie wystarczy zmierzyć czas?
Jednym z najprostszych sposobów, które zapewne prawie każdy programista kiedyś użył, jest zmierzenie różnicy między czasem przed i po wykonaniu operacji. Niestety nie zawsze taki pomiar będzie miarodajny – choćby z powodu w jaki współczesne procesory zarządzają zegarem. Standardowo dla oszczędności energii jest on przetaktowywany „w dół” i szybko podnoszony w sytuacji większego zapotrzebowania. Problem polega na tym, że zwiększenie częstotliwości, z jaką działa procesor wpływa na niemiarodajność wyniku czasu wykonania algorytmu. Co więcej, bieżące taktowanie może być nieprzewidywalne, kiedy nie jest wymuszone większym obciążeniem.
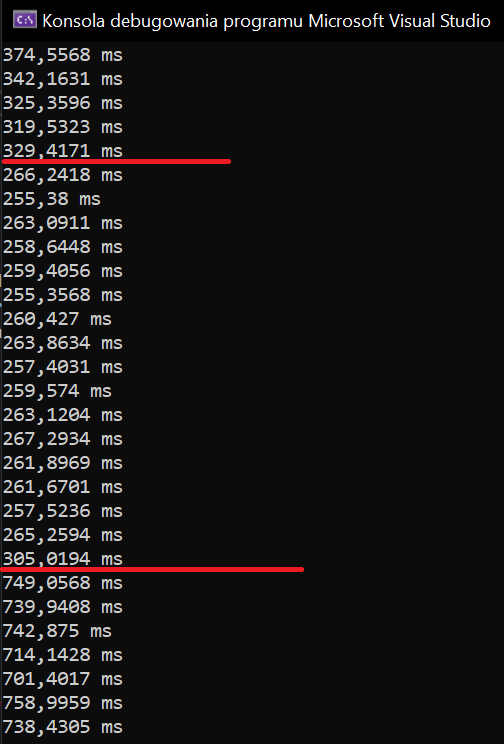
Można przeprowadzić operację mierzenia czasu wielokrotnego wykonania algorytmu i uśrednić go. Tu pojawiają się kolejne problemy, np. procesory Intel w trybie Boost są w stanie pracować przez ograniczony czas, a jeśli benchmark trwa dłużej, to wynik zostanie wypaczony. Na Rys. 1. widać symulację takiego zachowania. Przedstawiony program generuje tablicę z milionem elementów, a następnie sortuje ją przy pomocy LINQ. Pierwsze kilka wywołań potrzebuje wyraźnie więcej czasu niż kolejne. Na końcu uruchomiono symulację końca trybu boost poprzez ograniczenie zegara do 80% poprzedniej wartości, co dało prawie trzykrotnie dłuższy czas.
Rys. 1. Symulacja różnicy wykonania algorytmu w zależności od taktowania procesora
Możemy zacząć implementować obliczanie odchylenia standardowego, odrzucać skrajne 5% wyników i korzystać z innych sztuczek statystycznych… Czyli robić to, co BenchmarkDotNet od razu zrobi za nas.
W pierwszym kroku utwórzmy nowy projekt. BenchmarkDotNet napisany jest w .NET Standard 2.0, co oznacza, że możemy z niego korzystać zarówno w .NET Core 2.0 jak i w .NET Framework 4.6 oraz w wersjach nowszych [3]https://benchmarkdotnet.org/articles/overview.html.
Bibliotekę do projektu można dodać przy pomocy Menedżera pakietów Nuget szukając w nim BenchmarkDotNet lub z poziomu Konsoli menedżera pakietów wpisując do niej Install-Package BenchmarkDotNet.
Pierwszy benchmark
public class GenerateSortedArrayBenchmark
{
[Benchmark]
public int[] ClassicGenerateAndSortUsingLinq()
{
var array = new int[1_000_000];
var rnd = new Random(42);
for (int i = 0; i < array.Length; ++i)
{
array[i] = rnd.Next();
}
return array.OrderBy(i => i).ToArray();
}
}
Tworzymy klasę GenerateSortedArrayBenchmark, w której umieszczamy pierwszą metodę, nazwijmy ją ClassicGenerateAndSortUsingLinq. Przed metodą dodajemy adnotację [Benchmark]. Ważne, aby zarówno klasa, jak i metoda był widoczne publicznie.
Aby uruchomić test zmodyfikujmy Main startując w nim benchmark.
Ostatnim krokiem jest skompilowanie kodu w konfiguracji Release. Jest to ważne, ponieważ w ten sposób kompilator zaaplikuje optymalizacje, a wygenerowany kod będzie taki, jak uruchamiany w środowisku produkcyjnym.
W końcu możemy uruchomić benchmark. Ważne, aby nie robić tego przez Visual Studio – dołączy on do programu debuger, który może spowalniać wykonanie. Uruchomienie pliku .exe może dać niechciany rezultat w postaci programu zamykającego się od razu po wykonaniu benchmarku – nie zdążymy obejrzeć wyników. Dodanie Console.ReadKey(); aby temu zapobiec nie zawsze jest dobrym rozwiązaniem – łatwo przypadkiem nacisnąć jakiś klawisz i stracić wyniki – co może być szczególnie dotkliwe w przypadku benchmarków, które wykonują się kilka minut i dłużej. Osobiście uruchamiam je przez PowerShell, natomiast dobrym nawykiem jest korzystanie z dowolnej konsoli – w tym wspomnianej już wcześniej Konsoli menedżera pakietów dostępnej bezpośrednio z poziomu Visual Studio.
Rys. 2. Pierwsze wyniki
Program po uruchomieniu wyświetli dużo informacji. Najważniejszą z nich jest tabelka widoczna na końcu wszystkich wiadomości, która pokazuje podstawowe informacje z benchmarku.
Dobrze byłoby do czegoś porównać…
Benchmarków używamy przede wszystkim do znajdowania szybszych implementacji i porównywania czasów różnych rozwiązań. Patrząc na poprzedni kod możemy pomyśleć, że zamiast tworzyć tablicę a następnie ją sortować, możemy skorzystać z mechanizmu, który od razu przy tworzeniu będzie automatycznie sortował za nas. Sprawdźmy, czy zadziała szybciej.
[Benchmark]
public int[] GenerateUsingSortedDictionary()
{
var dictionary = new SortedDictionary<int, int>();
var rnd = new Random(42);
for (var i = 0; i < 1000; ++i)
{
var randomNr = rnd.Next();
if (dictionary.ContainsKey(randomNr))
{
dictionary[randomNr]++;
}
else
{
dictionary.Add(randomNr, 1);
}
}
return dictionary.Keys.ToArray();
}
Rys. 3. Wyniki dwóch benchmarków
Kod z ostatniego benchmarku ma kilka problemów. Przede wszystkim nie zwróci dobrej tablicy w przypadku, jeśli wylosowane wartości będą się powtarzać (w tej implementacji zobaczymy tylko unikalne wartości). Nie musimy się tym jednak przejmować, ponieważ jest zdecydowanie zbyt wolny, aby w ogóle się nim zajmować.
Dodałem „po cichu” jedną zmianę w kodzie – przy pierwszym benchmarku zmieniłem adnotację [Benchmark] na [Benchmark(Baseline = true)]. Dzięki temu wynik drugiego benchmarka jest porównywany do pierwszego – kolumna ratio to iloczyn średniego czasu danego benchmarka przez wynik porównawczy.
[Benchmark]
public int[] GenerateAndQuickSort()
{
var array = new int[1_000_000];
var rnd = new Random(42);
for (var i = 0; i < array.Length; ++i)
{
array[i] = rnd.Next();
}
QuickSort(array, 0, array.Length-1);
return array;
}
private static void QuickSort(int[] array, int left, int right)
{
var i = left;
var j = right;
var pivot = array[(left + right) / 2];
while (i < j)
{
while (array[i] < pivot) ++i;
while (array[j] > pivot) --j;
if (i <= j)
{
var tmp = array[i];
array[i++] = array[j];
array[j--] = tmp;
}
}
if(left<j) QuickSort(array, left, j);
if(i < right) QuickSort(array, i, right);
}
Rys. 4. Wyniki pierwszego i trzeciego benchmarku
Parametryzacja i refaktoryzacja benchmarków
W poprzednim akapicie udało się otrzymać sortowanie trzy razy szybsze od LINQ. BenchmarkDotNet pozwala na łatwe porównanie czasów dla różnych wielkości tablic. W tym celu zrefaktoryzujmy nasze benchmarki i wprowadźmy parametry.
Kontrola wielkości tablicy dzięki parametrowi
BenchmarkDotNet pozwala na uruchomienie każdego z naszych benchmarków dla innej wielkości tablicy. Aby to osiągnąć wprowadźmy parametr N, którego następnie użyjemy w odpowiednich miejscach kodu.
[Params(100, 10_000, 1_000_000)]
public int N;
Adnotacja Params mówi narzędziu, jaką wartość wykorzystać do kolejnych benchmarków. W ten sposób program zamiast trzech benchmarków uruchomi ich tak naprawdę dziewięć.
Refaktoryzacja i GlobalSetup
W każdym z benchmarków powtarza się jedna linijka – inicjalizacja generatora losowych liczb. W ogólnym rozrachunku takiego kodu może być więcej. Chcąc unikać niepotrzebnych powtórzeń, wyciągnijmy go do funkcji inicjalizującej kod. Dzięki temu będziemy mieć pewność, że każdy benchmark będzie korzystał z generatora zainicjalizowanego w taki sam sposób (i nie zapomnieliśmy nigdzie dodać ziarna).
private Random rnd;
[GlobalSetup]
public void Setup()
{
rnd = new Random(42);
}
Adnotacja GlobalSetup mówi BenchmarkDotNet, aby tej metody użyć przed każdą iteracją każdego benchmarku.
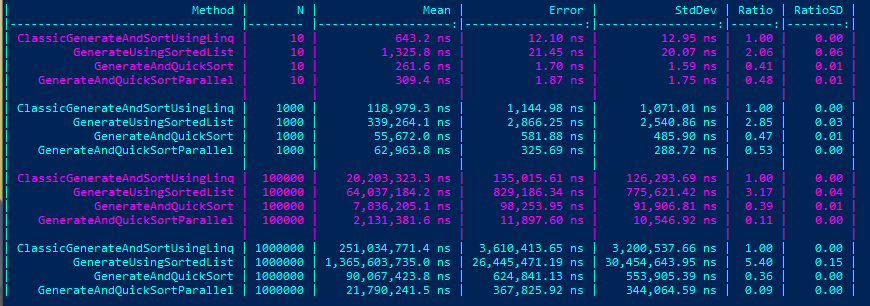
Ostateczne wyniki
Rys. 5. Ostateczne wyniki wszystkich benchmarków
Kod oczywiście może być jeszcze przyspieszony, szczególnie dla większych wartości N, np. poprzez wykorzystanie więcej niż jednego wątku. W wynikach widzimy benchmark, który mimo niewielkiej zmianie w kodzie dał 75% wzrostu wydajności dla dużych tablic.
Sam BenchmarkDotNet oprócz tego umożliwia więcej możliwości konfiguracji, mierzenie ilości alokacji oraz zużycie pamięci przez algorytm. Wkrótce pojawią się kolejne artykuły opisujące tego typu scenariusze.
Najnowsze funkcjonalności .NET Core 3.0 mimo tego, że istnieją już od ponad roku, wciąż rzadko są stosowane w aplikacjach. W artykule przyjrzyjmy się, jakie korzyści mogą wynikać z wykorzystania instrukcji AVX2 w nowoczesnym kodzie, a także zobaczymy powód, dla którego należy unikać stosowania LINQ w krytycznych częściach kodu.
Niedawno otrzymałem filmik opisujący kilka rad o tym, jak zwiększyć wydajność aplikacji, dzięki pewnym sztuczkom. Zainteresowanych jego treścią odsyłam do źródła[1]5 (Extreme) Performance Tips in C#. Dlaczego wspominam o nim? Autor przedstawia kilka ciekawych sztuczek optymalizacyjnych, jednak całkowicie pomija hardware intrinsics – pewnego rodzaju nowinkę, dodaną w .NET Core 3.0, czyli trochę ponad rok temu.
Przyspieszenie sprzętowe?
Współczesne procesory architektury x86 zawierają w sobie wiele dodatkowych zestawów instrukcji. Jednym z nich jest Advanced Vector Extensions, czyli w skrócie AVX[2]Advanced Vector Extensions – Wikipedia. Umożliwia to wykonywanie operacji na wektorach, czyli zestawach liczb, co przekłada się na mniej cyklów procesora potrzebnych do otrzymania wyniku. Przykładowo, jeśli chcemy dodać do siebie 100 liczb, możemy dodawać je klasycznie, do pierwszej dodać drugą, do ich sumy trzecią, do tej sumy czwartą i tak dalej. Zajmie nam to dokładnie 100 cykli procesora, po jednym na każde dodawanie.
Zamiast tego możemy dodawać te liczby wektorem 8-elementowym – działa to w ten sposób, że w jednym cyklu procesora dodawany jest element pierwszy z dziewiątym, drugi z dziesiątym, trzeci z jedenastym i tak dalej. Dzięki temu potrzebujemy 12 cykli procesora na dodanie 96 elementów. Następnie te elementy sumujemy – co daje 8 cykli, a do ich sumy dodajemy brakujące cztery elementy, co daje kolejne 4 cykle. Łącznie 24 cykle zamiast 100.
Wszystko pięknie… Ale?
Ten wzrost wydajności ma swoje wymagania. Przede wszystkim – procesor, na którym będzie uruchamiany program musi zawierać zestaw rozkazów AVX – na szczęście większość współczesnym procesorów ją posiada. Oprócz tego z powodu, w jaki działają wektory, wymagane są wskaźniki do pamięci (jeśli Cię to dziwi – to tak, w C# można korzystać z wskaźników na tej samej zasadzie, co choćby w C++, więcej o tym wkrótce), co oznacza niebezpieczny (unsafe) kod. Wymaga to też odrobinę wiedzy, na szczęście to ostatnie właśnie Ci dostarczamy 🙂
Wymagania wstępne
Hardware Intrinsics wymaga .NET Core 3.0 lub nowszego oraz ustawienia flagi /unsafe w kompilatorze. Jeśli nie wiesz jak zainstalować .NET Core to najprawdopodobniej ten poradnik nie jest dla Ciebie, jednak nie zniechęcaj się – pobierzesz go bezpośrednio z strony Microsoftu[3]https://dotnet.microsoft.com/download/dotnet-core/.
Flagę /unsafe można dodać modyfikując plik projektu i ustawiając AllowUnsafeBlocks na true lub potwierdzając podpowiedź wyświetlaną przez Visual Studio.
Podpowiedź wygenerowana przez Visual Studio dodająca AllowUnsafeBlocks do pliku projektu
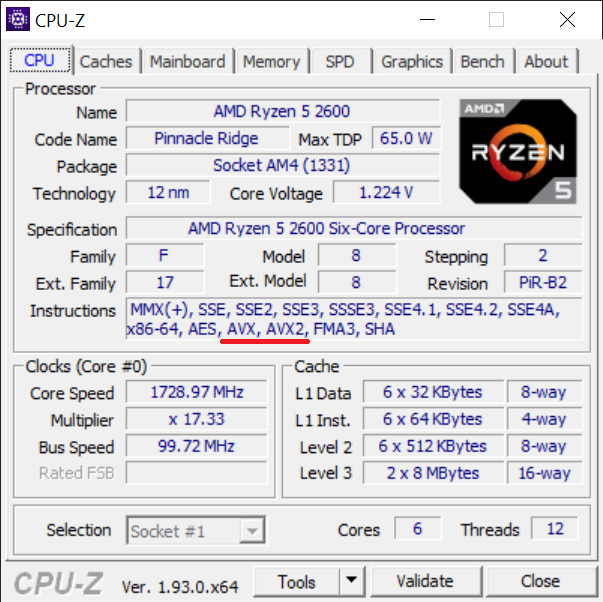
Jeśli nie posiadasz procesora z instrukcjami AVX – niestety nie będziesz w stanie sam sprawdzić, jak działa kod. Jeśli nie jesteś pewien czy go posiadasz, to program CPU-Z[4]CPUID website pokazuje wszystkie informacje na temat procesora, w tym czy implementuje on AVX.
Program CPU-Z z podkreślonymi instrukcjami AVX i AVX2 dla procesora AMD Ryzen 5 2600
Całkiem szybki kod bez Hardware Intrinsics
Najpierw zerknijmy na fragment kodu z wspomnianego filmiku, jeden z najszybszych a przy tym dość prosty. Dla osób, które nie oglądały filmiku – celem jest znalezienie jak najszybszej metody na zsumowanie wszystkich nieparzystych liczb z pewnej tablicy. Pełny kod można obejrzeć na naszym GitHubie[5]GitHub – HwIntrinsincsBenchmark
public int SumOdd()
{
var counterA = 0;
var counterB = 0;
var counterC = 0;
var counterD = 0;
unsafe
{
fixed (int* data = &array[0])
{
var p = data;
for (var i = 0; i < array.Length; i += 4)
{
counterA += (p[0] & 1) * p[0];
counterB += (p[1] & 1) * p[1];
counterC += (p[2] & 1) * p[2];
counterD += (p[3] & 1) * p[3];
p += 4;
}
}
}
return counterA + counterB + counterC + counterD;
}
Jest to odrobinę zmodyfikowana wersja przedostatniego przykładu z filmiku. Jedyną zmianą jest explicite dodanie bloku unsafe.
Kod choć niecodzienny, jest dość prosty, mamy cztery liczniki, do których dodajemy liczby, jeśli są nieparzyste. Wynika to z faktu, że operacja bitowego i (&) zwróci 1, jeśli ostatni bit ustawiony jest na 1 (czyli liczbę nieparzystą), w przeciwnym wypadku zwróci 0. Następnie mnożymy sprawdzaną liczbę razy tę zwróconą wartość, jak wiadomo 1 * liczba = liczba, 1 * 0 = 0. Jest to odrobinę szybszy sposób, niż instrukcja if.
Wykorzystanie AVX
public int SumUsingVectors()
{
int sum = 0;
var itemsCountUsingVectors = _array.Length - _array.Length % Vector256<int>.Count;
var template = Enumerable.Repeat(1, Vector256<int>.Count).ToArray();
var sumVector = Vector256<int>.Zero;
unsafe
{
Vector256<int> templateVector;
fixed (int* templatePtr = template)
{
templateVector = Avx.LoadVector256(templatePtr);
}
fixed (int* valuesPtr = _array)
{
for (var i = 0; i < itemsCountUsingVectors; i += Vector256<int>.Count)
{
var valuesVector = Avx.LoadVector256(valuesPtr + i);
var andVector = Avx2.And(valuesVector, templateVector);
var multiplyVector = Avx2.MultiplyLow(andVector, valuesVector);
sumVector = Avx2.Add(sumVector, multiplyVector);
}
}
}
for (var iVector = 0; iVector < Vector256<int>.Count; iVector++)
{
sum += sumVector.GetElement(iVector);
}
for (var i = itemsCountUsingVectors; i < _array.Length; i++)
{
sum += (_array[i] & 1) * _array[i];
}
return sum;
}
Na pierwszy rzut oka widać, że kod jest dłuższy, więc przejdźmy przez całość.
Na początku wyliczamy, ile maksymalnie elementów jesteśmy w stanie policzyć wektorami – jeśli w jednym wektorze zmieści się 8 elementów, to będzie to podłoga z dzielenia liczby wszystkich elementów przez 8 (np. 100/8 = 12.5, czyli możemy użyć maksymalnie dwunastu ośmioelementowych wektorów).
Następnie tworzymy tablicę zawierającą same „1” – przyda się później.
W kolejnym kroku tworzymy wektor, do którego będziemy sumować.
W tym miejscu wchodzimy do niebezpiecznego (unsafe) kodu. Pierwszym krokiem jest załadowanie tablicy zawierającej same „1” jako wektor. Używamy do tego wskaźnika pokazującego na początek tablicy.
Poniżej pobieramy kolejny wskaźnik – na tablicę, która zawiera dane. Następnie wchodzimy w pętlę, która wykona się tyle razy, ile na początku wyliczyliśmy, że jesteśmy w stanie obliczyć wektorami.
W środku pętli ładujemy do wektora wartości z tablicy, wykonujemy operację AND na nim oraz na wektorze z samymi jedynkami. Wynik tej operacji mnożymy przez wektor wartości, a iloczyn dodajemy do wektora z sumą.
Jeśli przez chwilę zastanowimy się nad zawartością pętli, to szybko zauważymy, że są to dokładnie te same operacje, które są wykorzystywane w środku pętli w filmiku z YouTube, tylko wykonywane na wektorach zamiast na liczbach: Avx2.And to odpowiednik &, Avx2.MultiplyLow to odpowiednik mnożenia, a Avx2.Add to odpowiednik dodawania.
Poza blokiem unsafe sumujemy wartości z wektora wynikowego do jednej liczby, a następnie do niej dodajemy brakujące elementy.
Benchmarki
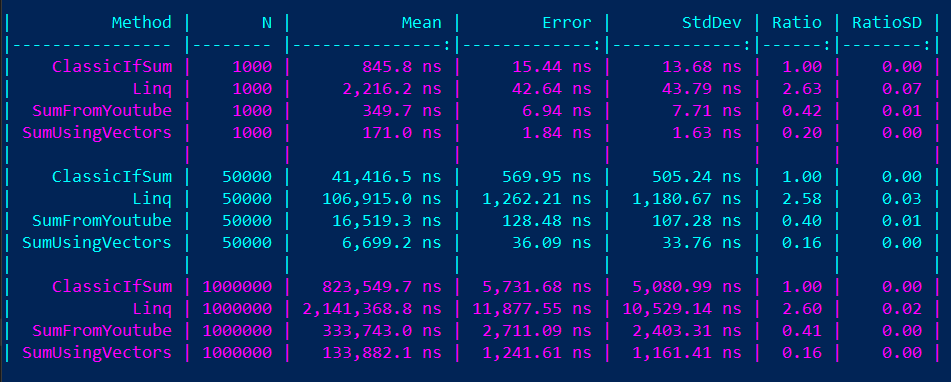
Poniżej dołączam screenshot z wynikami wygenerowanymi, dzięki Benchmark .NET[6]Mierzenie wydajności implementacji dzięki BenchmarkDotNet, ClassicIfSum to najbardziej standardowy algorytm do tego typu obliczeń, zawierający if i operację modulo 2. Do niego porównujemy pozostałe wyniki. SumFromYoutube to oczywiście kod zaczerpnięty z filmiku, SumUsingVectors to nasza implementacja. Dodałem do tego wywołanie przy pomocy LINQ: _array.Where(t => t % 2 != 0).Sum(); zdecydowanie najprostsze do zakodowania i zdecydowanie najwolniejsze.
Z wyników widać, że optymalizacja YouTubera dała 58-60% wzrostu wydajności w porównaniu do bazy, natomiast nasza dała 61% wzrostu wydajności w porównaniu do kodu YouTubera i aż 84% w porównaniu do klasycznej implementacji.
Dodatkowo LINQ było wolniejsze o odpowiednio 633% do nawet 1610% w przypadku naszego kodu.
Wyniki uruchomionych benchmarków
Na koniec dodam, że kod ten można jeszcze przyspieszyć, wykorzystując wyrównanie pamięci, jednak jest to temat na osobny artykuł. Jeśli jesteście nim zainteresowani to dajcie znać!
Podsumowanie
Najnowsze wersje .NET dają bardzo dużo narzędzi do pogłębienia optymalizacji kodu w współczesnych aplikacjach. Dzięki najnowszym funkcjonalnościom możemy pisać kod szybszy niż kiedykolwiek wcześniej. Z analizy benchmarków dowiedzieliśmy się też, żeby nie używać LINQ w miejscach, które są krytyczne dla wydajności systemu.